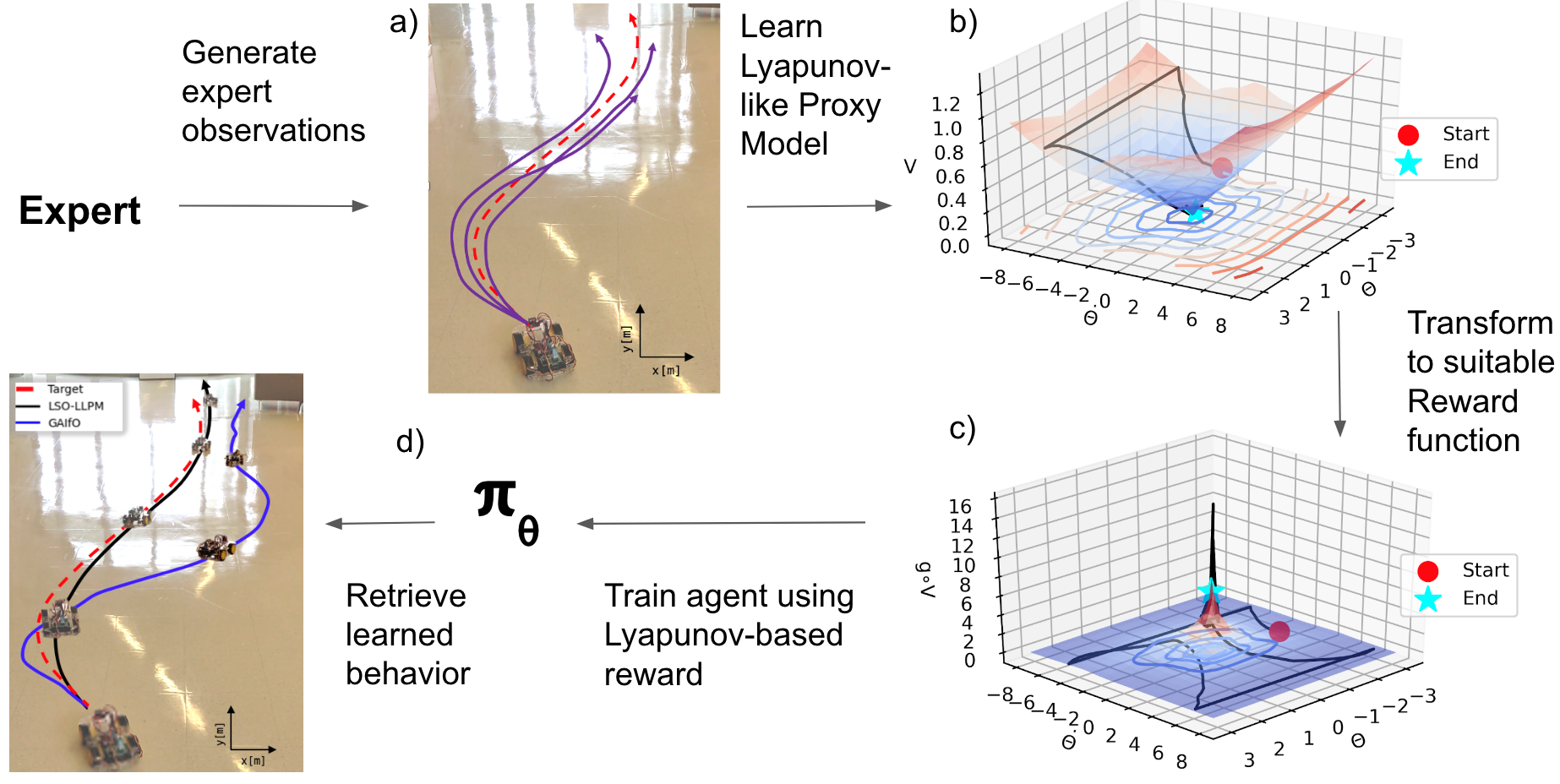
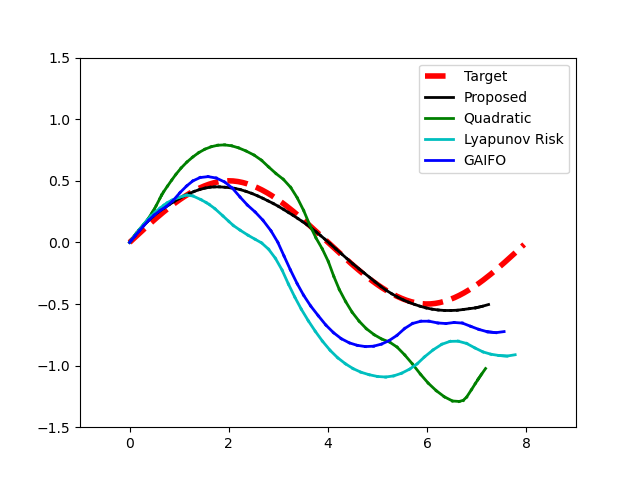
Overall algorithm:
@inproceedings{ganai2023lsollpm,
author={Ganai, Milan and Hirayama, Chiaki and Chang, Ya-Chien and Gao, Sicun},
booktitle={2023 IEEE International Conference on Robotics and Automation (ICRA)},
title={Learning Stabilization Control from Observations by Learning Lyapunov-like Proxy Models},
year={2023},
pages={2913-2920}
}