Discovered Reasoning Distributions
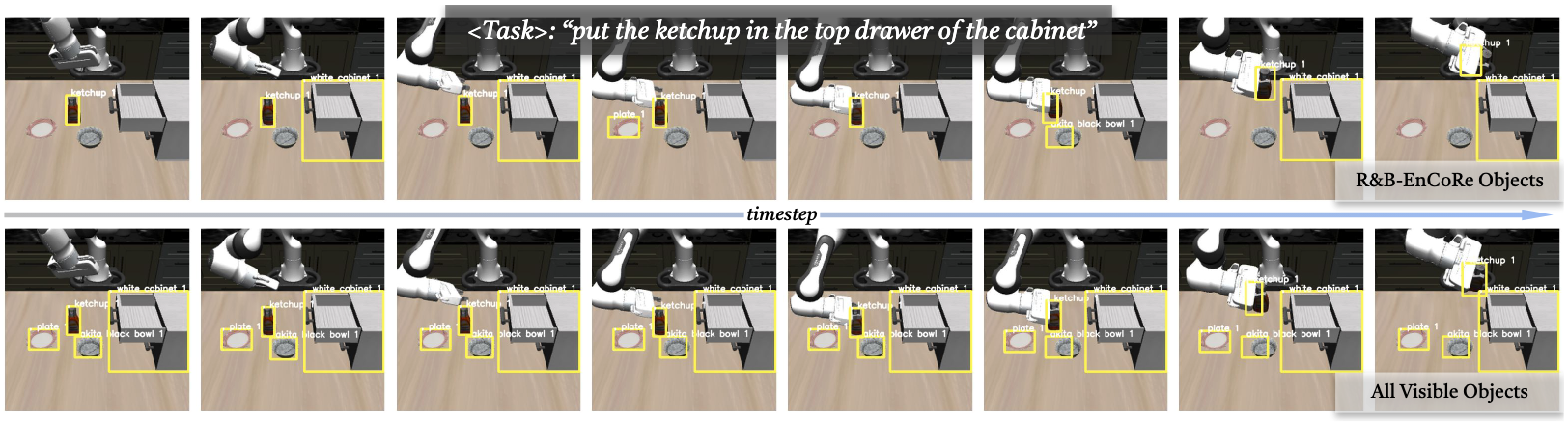
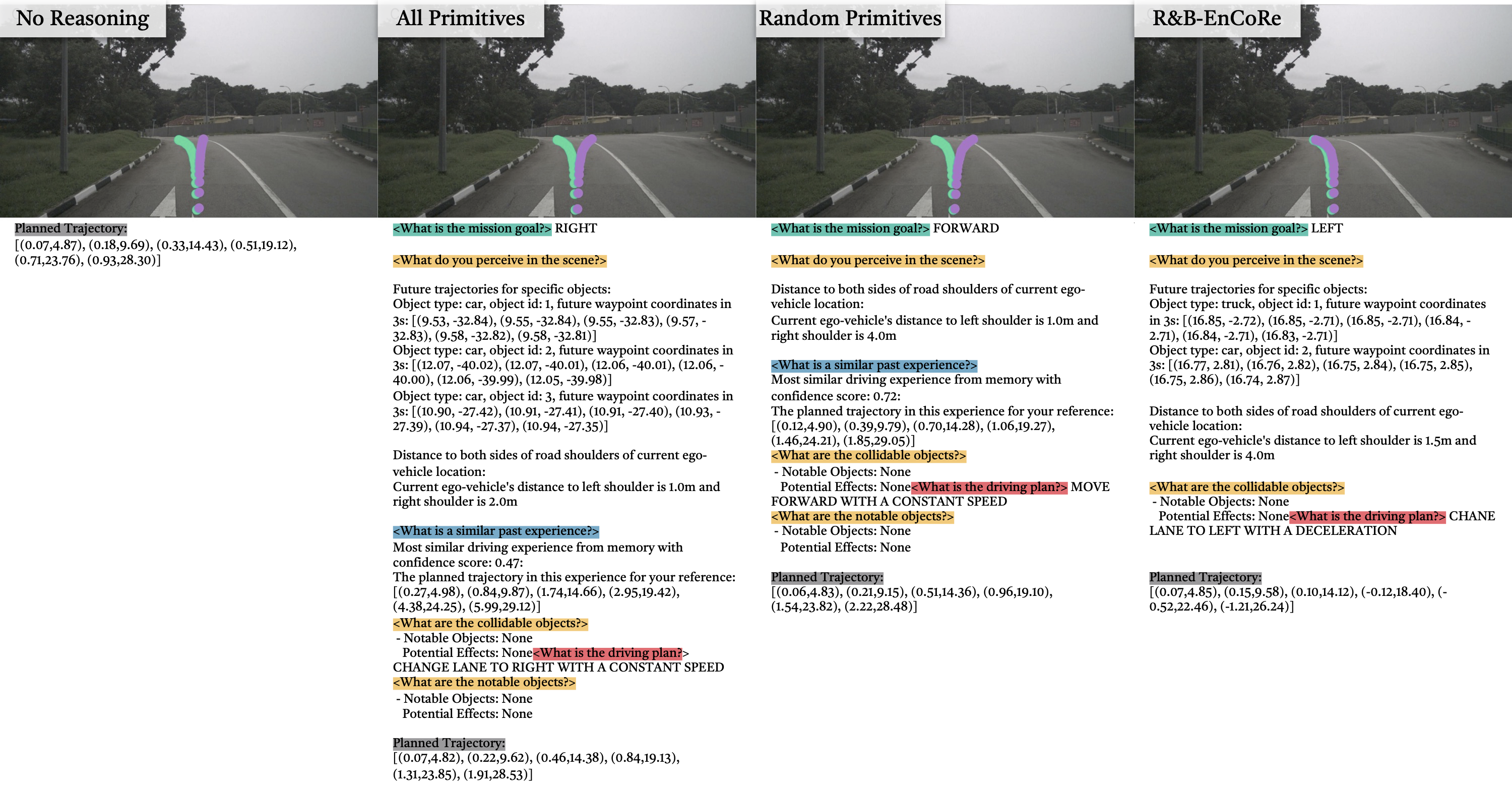
R&B-EnCoRe autonomously discovers distinct, interpretable reasoning distributions tailored to each embodiment — without any external supervision, reward signals, or human annotation. Rather than applying a single "one-size-fits-all" template, the framework identifies which reasoning primitives are genuinely predictive of successful control for each embodiment and task type.

Reasoning primitive distributions across domains. (a) Manipulation: differences between Franka Panda (simulation) and WidowX (hardware) — notably in Visible Objects, Move Explain, and Subtask Explain. Concise Move and Gripper Position primitives dominate, while verbose explanations and distracting details are pruned. (b) Legged navigation: structural affordances are consistently critical across all four embodiments (bipedal, wheeled, bicycle, quadruped); counterfactual reasoning is selectively used. (c) Autonomous driving: reasoning concentrates on mission goals and constraints in the form of notable and collidable objects.